재표본추출이란 ?
통계학에서 재표본추출의 목표는 랜덤한 변동성을 알아보기 위함이다. 재표본추출은 표본을 반복적으로 추출하는 것을 의미한다. 이를 적용하면 머신러닝 모델의 정확성을 평가하고, 향상시킬 수 있다.
[ 재표본추출의 유형 ]
1 ) 부트스트랩
2 ) 순열 검정
재표본추출은 여러 표본이 결합되어 비복원추출을 수행할 수 있는 순열 과정을 포함하는 반면, 부트스트랩은 항상 관측된 데이터로부터 복원 추출한다. 부트스트랩은 추정의 신뢰성을 평가하는데 사용된다.
1. 부트스트랩( bootstrap )
어원
pull your self up by your bootstraps이라는 말에서 유래되었다. 외부의 도움 없이 어떤 과정을 수행해나갈 수 있음을 의미한다.
장점
1 ) 데이터셋의 분포가 고르지 않은 경우에 사용될 수 있다.
왜 ?
증명하기 힘든 가정을 전제로 시작하지 않는다.
( 기존의 통계방법은 증명하기 힘든 가정을 전제로 시작한다 )
EX )
train set에 사과 1만장, 오렌지 100장의 사진이 있다. 이를 분류할 때 당연히 99%의 정확도를 보일 것이다.
균형을 맞추는 방법은 세 가지가 있다.
① weight를 줄 수 있는 알고리즘 사용
② bootstraping으로 오렌지 데이터 수 증가시키기
③ 사과 데이터 수 줄이기
2 ) over-fitting을 줄이는 데 도움이 된다. ( = bagging )
왜 ?
model ensemble의 각 모델이 over-fitting 되어있더라도, 그들을 평균내면 서로 상쇄되어 더 일반적인 모델이 되기 때문에 안정성을 크게 높일 수 있다.
과정
bootstrp : 현재 있는 표본에서 추가적으로 표본을 복원추출(m)하고 각 표본에 대한 통계량과 모델을 다시 계산하는 것
이렇게 보면 원래 표본을 수천, 수백만 번 복제하는 것처럼 보이지만 반복 복제한다는 것이 아니다.
뽑을 때 마다 각 원소가 뽑힐 확률은 그대로 유지하면서 무한한 크기의 모집단을 만들어낼 수 있다.
크기 n의 샘플의 평균을 구하는 부트스트랩 재표본추출 알고리즘을 살펴보자.

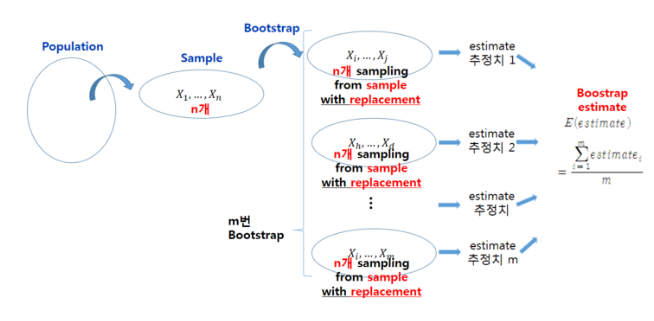
1 ) 샘플 값을 하나 뽑아서 기록하고 제자리에 놓는다
2 ) n번 반복한다
3 ) 재표본추출된 값의 평균을 기록한다
4 ) 1 ~ 3을 m번 반복한다 ( 중복 허용 )
5 ) m개의 결과를 사용하여 표준편차를 계산한다
반복 횟수가 많을수록 표준오차나 신뢰구간에 대한 추정이 더 정확해진다 !
부트스트랩에 대하여 (Bootstrapping)
언젠가 회사에서 ‘bootstrapping’이라는 단어를 들었는데 그 뜻이 내가 아는 것과 다른 듯 했다. 그래서 후에 관련 내용을 찾아보게 되었고, 그 내용을 다시 요약하여 여기에 정리한다. 통계학에서의 부트스트랩 (Bootstrap in statistics) 일단 “bootstrapping”이란 용어는 통…
learningcarrot.wordpress.com
bootstrap 붓스트랩 in machine learning
# 방법 m 번 (m=1,000 ~ 2,000) 동안 반복한다.1.1. sample 개수 n 만큼 복원 추출한다.1.2. 복원 추출한 s...
blog.naver.com
귀퉁이 서재 코드 구현을 볼 수 있어서 좋음 !
2. 순열 검정 ( permute test )
어원
어떤 값들의 집합에서 값들의 순서를 변경한다
과정
무작위 순열 검정(random permutation test) = 임의순열검정, 임의화검정
: 두 개 이상의 표본을 함께 결합하여 관측값들을 무작위로 재표본으로 추출하는 과정
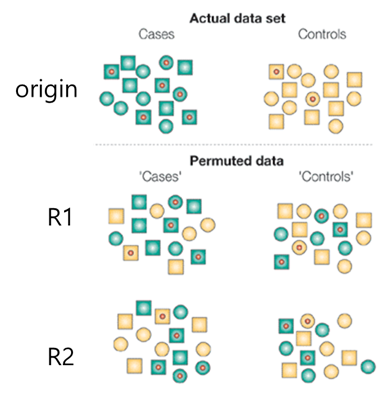
1 ) 여러 그룹의 결과를 단일 데이터 집합으로 결합한다
2 ) 결합된 데이터를 잘 섞은 후, 그룹 A와 동일한 크기의 표본을 무작위로 (비복원) 추출한다
3 ) 나머지 데이터에서 그룹 B와 동일한 크기의 샘플을 무작위로 (비복원) 추출한다
4 ) 지금 추출한 재표본에 대해 모두 다시 계산하고 기록한다
5 ) 1 ~ 4의 과정을 R번 반복하여 검정통계량의 순열 분포를 얻는다
결과
기존 그룹의 차이와 순열 과정에서 얻은 집합의 차이를 비교해보자.
만약, 기존 차이가 순열로 나온 차이의 집합 안에 들어가 있다면 어떠한 것도 증명할 수가 없다.( 우연히 일어날 수 있음 )
하지만, 기존 차이가 순열 분포의 바깥에 있다면, 우연 때문이 아니라고 결론 내릴 수 있다.
즉, 통계적으로 유의미하다.
순열 검정의 변종
순열 검정에는 두 가지 변종이 있다.
1 ) 전체 순열 검정 ( exhaustive permutation test )
2 ) 부트스트랩 순열 검정 ( bootstrap permutation test )
1. 전체순열검정 : 데이터를 무작위로 섞고 나누는 과정에서 나눌 수 있는 모든 가능한 조합을 찾는다.
따라서 샘플 크기가 비교적 작을 때만 실용적이다. 셔플링을 많이 반복할수록, 임의순열검정 결과는 전체순열검정 결과와 유사하게 근접한다. '유의미하다'라는 결론이 아닌 더 정확한 결론을 보장하는 통계적 속성이 있어서 '정확검정'이라고도 한다.
2. 부트스트랩 순열검정 : 무작위 순열검정의 2,3단계에서 비복원으로 하던 것을 복원 추출로 수행한다.
이는 리샘플링 과정에서 모집단 개체를 선택할 때, 개체가 다시 그룹에 할당될 때에도 임의성을 보장한다.
하지만, 이를 구별하는 일이 복잡하고, 데이터 과학에서 별로 실용적이지 않다.
'AI > Statistics' 카테고리의 다른 글
| 05. t검정( t -test ) (0) | 2020.05.11 |
|---|---|
| 04. 통계적 유의성과 p-value (0) | 2020.05.10 |
| 02. 가설 검정 (0) | 2020.05.08 |
| 01. A / B 검정 (0) | 2020.05.08 |
| 00. 통계적 실험과 유의성 검정 개요 (0) | 2020.05.08 |