다중검정이란?
다중검정은 검정군이 3가지이상인 경우에 5%의 유의수준으로 유의미하다고 말할 수 있을까? 로부터 시작된다.
예를 들어 실험군이 1000개가 있다.
실험군 1이 나머지 999개의 실험군보다 p<0.05 로 유미하게 차이가 난다고 하면,
실험군 1이 2와 유의미한 차이가 나지 않지만, 차이가 난다고 잘못 결과를 내릴 확률(1종오류)은 5%이다.
실험군 1이 3와 유의미한 차이가 나지 않지만, 차이가 난다고 잘못 결과를 내릴 확률(1종오류)은 5%이다.
실험군 1이 4와 유의미한 차이가 나지 않지만, 차이가 난다고 잘못 결과를 내릴 확률(1종오류)은 5%이다.
...
실험군 1이 999와 유의미한 차이가 나지 않지만, 차이가 난다고 잘못 결과를 내릴 확률(1종오류)은 5%이다.
// 수정필요
이 확률을 모두 곱하면 999 * 0.05 = 약 50이다.
즉, 50개의 검정이 잘못되었을 수 있다.
이런 문제를 다중 검정 비교의 문제(multiple comparison problem, MCP)라고 한다.
따라서 다중 검정인 경우에는 p-value설정 만으로 끝나는 것이 아니라 '사후 분석(post hoc)'을 해주어야한다.
사후 분석의 방법에는 본페로니, 던컨 등등의 방법이 있고 현재는 FDR(False Discovery Rate)를 가장 많이 사용한다.
사후 분석을 통해 다중비교문제를 보정한 p-value를 corrected p라고 한다.
다중 검정 보정 방법
1. 본페로니(bonferonni) 보정 방법
FWER( Family-Wise 1 Error Rate ) : 한 연구에서 적어도 한 개의 잘못된 결론이 나올 수 있는 확률
FWER을 통제하기 위한 방법 중 본페로니 보정 방법이 있다. test의 수가 n이고, FWER을 0.05로 통제할 때, 개별 테스트의 유의 수준을 alpha/m 으로 설정한다. 모든 검정이 실제로 연관성이 없을 때는 m이 클수록 대략적으로 만족시킨다.

하지만, 이 방법은 너무 보수적(귀무가설을 웬만하면 기각하지 않는다)이기 때문에, FP는 줄일 수 있지만 FN은 많아진다.
test 수 = 1000개
연관성이 없는 것 = 900개
연관성이 있는 것 = 100개
900개 중에 1개라도 잘못 나올 확률 = 1 - (1 - 0.05 / 1000)^900 < 0.05이다.
2. Multi-step 보정 방법
step-down, step-up 방법으로 나뉜다.
step-down 방법에는 Holm's방법이 있고, step-up 방법에는 Hochberg 방법이 있다.
step-down은 p-value가 작은 검정부터 , step-up은 p-value가 큰 검정부터 귀무가설의 기각 여부를 보게 된다.
이러한 방법들은 FWER은 그대로 두면서 FN을 줄이는 방법으로 알려져 있다. 따라서 본페로니 방법보다 효율적이라는 것이 많이 알려져 있다. 이 방법은 모든 검정에서 나온 p-value를 정렬한 뒤, 각 검정마다 각기 다른 p-value cutoff를 적용시키는 방법이다.
3. FDR( False Discovery Rate )
FDR을 다중검정에서 사용할 때의 의미는 FP, FN으로의 집중이 아니라 내가 귀무가설을 기각한 검정 중 틀린 것의 비율을 줄이자는 것이다. FDR 통제에 많이 쓰이는 방법 중 하나로 Benjamin-Hochberg 방법이 있다.
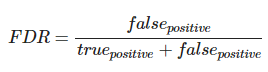
데이터 과학자의 결론
위의 방법들은 정의가 분명하며, 이미 잘 구조화된 통계 검정을 위한 수정 절차이다. 하지만 데이터 과학자들이 일반적으로 사용하기에는 너무 특정한 경우를 위한 것이기 때문에 문제에 맞게 변경하는 것이 어렵다. 따라서, 중복에 대한 데이터 과학자들의 결론은 다음과 같다.
1. 예측 모델링의 경우, 교차 타당성 검사 / 홀드아웃 표본을 사용하여, 실제 우연히 발생한 것을 겉보기에 유효한 것처럼 보이도록 잘못된 모델을 만들 위험을 낮춘다.
2. 미리 분류되어 있는 홀드아웃 표본이 없는 다른 절차의 경우, 데이터를 더 여러 번 사용하고 조작할수록 우연이 더 큰 역할을 할 수 있음을 인식해야한다. 또한 재표본 추출과 시뮬레이션 결과들을 사용하여 무작위 모델의 기준값을 만들어 관찰된 결과를 비교해야 한다.
다중 비교 (Multiple comparison) 문제와 보정 방법
다중 비교 (Multiple comparison) 문제와 보정 방법 본 포스팅에서는 다중 비교가 무엇인지, 어떤 방법으로 보정할 수 있는지를 알아보겠습니다. 다중 분석이 문제가 된다는 점을 이해하기 위해 먼저 �
3months.tistory.com
5% 유의수준과 다중비교
어떤 치료법의 효능에 대해 임상시험을 수행해 보면 통계적으로 유의한 효과를 보이는 경우도 있고, 효과가 입증되지 못하는 경우도 있다. 하지만 이러한 통계 결과는 항상 옳을까? 그렇지 않다
dermabae.tistory.com
'AI > Statistics' 카테고리의 다른 글
| 08. 분산분석( ANOVA ) (0) | 2020.05.17 |
|---|---|
| 07. 자유도( degree of freedom ) (6) | 2020.05.14 |
| 05. t검정( t -test ) (0) | 2020.05.11 |
| 04. 통계적 유의성과 p-value (0) | 2020.05.10 |
| 03. 재표본추출 (0) | 2020.05.09 |