서포트 벡터 머신( Support Vector Machine )
서포트 벡터 머신은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다.
결정 경계(Decision Boundary), 기준 선을 정의하여 어느 쪽에 속하는지 확인하여 분류를 하는 것이다.
최적의 결정 경계(Decision Boundary)
다른 그림으로 얼마나 많은 선을 그을 수 있을지 살펴보자면?

가운데 색칠된 부분에서 기울기를 만족한다면, 모든 선은 결정 경계가 될 수 있다.
따라서 똑같은 군집이 있더라도 다음과 같이 결정 경계를 설정할 수 있다.
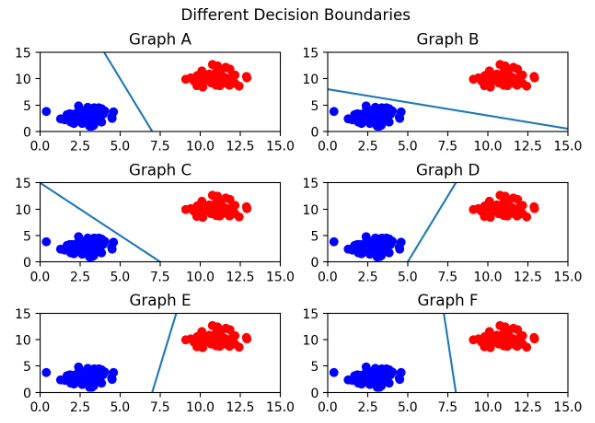
각 그룹의 선을 살펴보았을 때, 그룹C는 파란 점과 너무 가까워서 아슬아슬해보인다.
그렇다면 가장 안정적이어 보이는 결정 경계는 ? 아마 F일 것이다. 두 분류에서 거리가 가장 멀기 때문이다.
그러므로 결정 경계는 데이터 군으로부터 최대한 멀리 떨어지는 게 좋다.
마진( margin )
Support Vectors는 결정 경계(선)와 가까이 있는 벡터(점)들을 의미한다. 마진(Margin)은 결정 경계와 서포트 벡터 사이의 거리를 의미한다. ( = 기준선과 점들 사이의 거리 )

초록색 선이 마진이다.
따라서 최적의 결정 경계는 마진을 최대화한다.
그리고 n개의 속성을 가진 데이터에는 최소 n+1개의 서포트 벡터가 존재한다.
이진 클래스 분류
1 ) 선형
예시를 살펴보자.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5, ax=ax, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{}".format(clf.__class__.__name__))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend()
결정 경계를 조정하기 위해 매개변수(C)를 사용할 수 있다. C는 L2 규제의 강도를 결정하며, C의 값이 높아지면 규제가 감소하여 훈련 세트에 가능한 최대로 맞추려한다. 반면에 C 값을 낮추면 모델은 계수 벡터(W)가 0에 가까워지도록 만든다. 즉, C의 값이 높다면 각각의 점들이 중요해져서 point를 정확하게 분류하려고 할 것이다.
mglearn.plots.plot_linear_svc_regularization()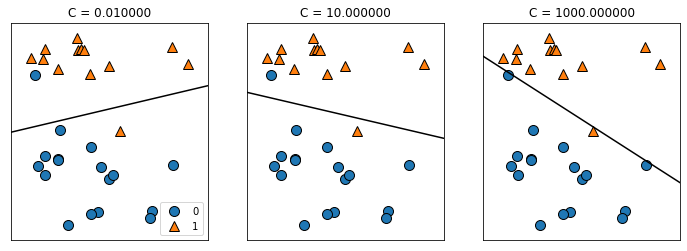
2 ) 비선형
만약 데이터가 다음과 같다면 어떻게 선을 그려볼 수 있을까?
X, y = make_blobs(centers=4, random_state=8)
y = y % 2
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("feature 0")
plt.ylabel("feature 1")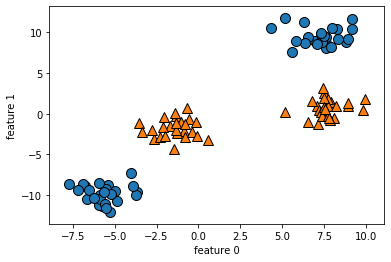
선을 그어본다면?
from sklearn.svm import LinearSVC
linear_svm = LinearSVC().fit(X,y)
mglearn.plots.plot_2d_separator(linear_svm, X)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("feature 0")
plt.ylabel("feature 1")
잘 분류가 안된다. 전혀 의미가 없구만.!
따라서 다음과 같이 약간 변형한다.
# 두 번째 특성을 제곱하여 추가
X_new = np.hstack([X, X[:, 1:] ** 2])3개의 열을 2차원 평면에 나타내기 어려우므로 3차원 그래프를 그려보자.
# 3차원 그래프를 그리기 위해 module import
from mpl_toolkits.mplot3d import Axes3D, axes3d
figure = plt.figure()
# 3차원 그래프
# elev : 어떤 방향에서 볼까? 위아래 조절
# azim : 어떤 방향에서 볼까? 오왼쪽 조절
ax = Axes3D(figure, elev=-152, azim=-26)
# y == 0인 포인트를 먼저 그리고 그다음 y == 1인 포인트를 그립니다.
mask = y == 0
ax.scatter(X_new[mask, 0], X_new[mask, 1], X_new[mask, 2], c='b',
cmap=mglearn.cm2, s=60, edgecolor='k')
ax.scatter(X_new[~mask, 0], X_new[~mask, 1], X_new[~mask, 2], c='r', marker='^',
cmap=mglearn.cm2, s=60, edgecolor='k')
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
ax.set_zlabel("feature 1 ** 2")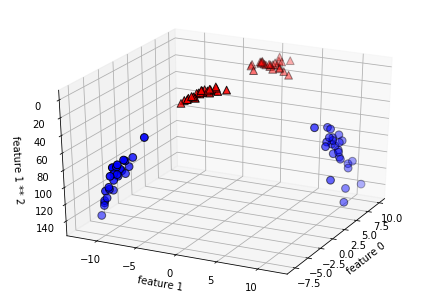
이 그래프를 보니 위쪽에 빨간색이, 아래쪽에 파란색이 몰려 있는 것 같다.
이를 구분해줄 결정 경계를 그리면 아마 '면'이 될 것이다. 그려보자.
# 위에서 사용한 데이터
linear_svm_3d = LinearSVC().fit(X_new, y)
coef, intercept = linear_svm_3d.coef_.ravel(), linear_svm_3d.intercept_
# 선형 결정 경계 그리기
figure = plt.figure()
ax = Axes3D(figure, elev=-152, azim=-26)
# np.linspace(start, end, nums)
xx = np.linspace(X_new[:, 0].min() - 2, X_new[:, 0].max() + 2, 50)
yy = np.linspace(X_new[:, 1].min() - 2, X_new[:, 1].max() + 2, 50)
# grid의 축값 조정
XX, YY = np.meshgrid(xx,yy)
# ZZ 값은 왜 이렇게 계산되는거지?
ZZ = (coef[0] * XX + coef[1] * YY + intercept) / -coef[2]
# 표면 그리기
ax.plot_surface(XX, YY, ZZ, rstride=8, cstride=8, alpha=0.5, color='lightgreen')
# 원본 데이터 그리기
ax.scatter(X_new[mask, 0], X_new[mask, 1], X_new[mask, 2], c='b',
cmap=mglearn.cm2, s=60, edgecolor='k')
ax.scatter(X_new[~mask, 0], X_new[~mask, 1], X_new[~mask, 2], c='r', marker='^',
cmap=mglearn.cm2, s=60, edgecolor='k')
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
ax.set_zlabel("feature 1 ** 2")
이를 원래 특성으로 투영해보자.
ZZ = YY ** 2
# np.ravel : 다차원 배열을 1차원으로 데이터 변환
dec = linear_svm_3d.decision_function(np.c_[XX.ravel(), YY.ravel(), ZZ.ravel()])
# plt.contourf : 등고선을 그려준다
plt.contourf(XX, YY, dec.reshape(XX.shape), levels=[dec.min(), 0, dec.max()],
cmap=mglearn.cm2, alpha=0.5)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("feature 0")
plt.ylabel("feature 1")
3 ) 커널 기법
위에선 특성이 3개였다. 만약 특성이 100개라면 연산 비용이 커지므로 수학적 기교를 사용해서 새로운 특성을 많이 만들지 않고서도 고차원에서 분류기를 학습시킬 수 있다. 이를 커널 기법이라고 한다.
사용하는 방법은 1 ) 다항식 커널 2 ) 가우시안 커널( = RBF 커널) 이 있다. 가우시안 커널은 모든 차수의 모든 다항식을 고려한다. 하지만 특성의 중요도는 고차항이 될수록 줄어든다.
RBF 커널을 사용해 SVM을 학습시켜 그래프를 그려보자.
from sklearn.svm import SVC
X, y = mglearn.tools.make_handcrafted_dataset()
# 학습
svm = SVC(kernel='rbf', C=10, gamma=0.1).fit(X, y)
mglearn.plots.plot_2d_separator(svm, X, eps=.5)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
# 서포트 벡터
sv = svm.support_vectors_
# dual_coef_의 부호에 의해 서포트 벡터의 클래스 레이블이 결정된다
sv_labels = svm.dual_coef_.ravel() > 0
mglearn.discrete_scatter(sv[:, 0], sv[:, 1], sv_labels, s=15, markeredgewidth=3)
plt.xlabel("feature 0")
plt.ylabel("feature 1")
C와 gamma의 매개변수를 조정하면서 선이 어떻게 변하는지 그려보자.
C는 값이 커질수록 각 point를 잘 분류하고자 한다. gamma는 각 point가 미치는 영향의 범위를 결정하므로 작은 값은 넓은 영역, 큰 값은 영향이 미치는 범위가 제한적이다.
fig, axes = plt.subplots(3, 3, figsize=(15, 10))
for ax, C in zip(axes, [-1, 0, 3]):
for a, gamma in zip(ax, range(-1, 2)):
mglearn.plots.plot_svm(log_C=C, log_gamma=gamma, ax=a)
axes[0, 0].legend(["class 0", "class 1", "class 0 support vector", "class 1 support vector"],
ncol=4, loc=(.9, 1.2))
gamma가 증가하면서 하나의 점에 민감해지므로 복잡한 모델을 만든다.
C가 증가하면서 결정 경계를 휘어 정확하게 분류한다.
장점
다양한 데이터셋에서 잘 작동한다.
데이터의 특성이 몇 개 안되더라도 복잡한 결정 경계를 만들 수 있다.
모든 특성이 비슷한 단위이고 스케일이 비슷하면 SVM을 시도해보면 좋다.
단점
저차원과 고차원의 데이터에 모두 잘 작동하지만 샘플이 많을 때는 맞지 않다.
10,000개 이상의 데이터셋에서 속도, 메모리 관점에서는 한계가 있다.
데이터 전처리와 매개변수 설정에 신경을 많이 써야한다. ( 요즘은 랜덤 포레스트, 그래디언트 부스팅 트리기반 모델 많이 사용)
결과를 분석하기가 어렵고 예측이 어떻게 결정되었는지도 이해하기도 어렵다.
2.3.7 커널 서포트 벡터 머신
2.3.6 결정 트리의 앙상블 | 목차 | 2.3.8 신경망(딥러닝) – 다음으로 다룰 지도 학습 모델은 커널 서포트 벡터 머신kernelized support vector machines입니다. 86페이지 “분류용 선형 모델”에서 선형 서포
tensorflow.blog
서포트 벡터 머신(Support Vector Machine) 쉽게 이해하기 - 아무튼 워라밸
서포트 벡터 머신은 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다. 일단 이 SVM의 개념만 최대한 쉽게 설명해본다. 결정 경계, 하드 마진과 소프트 마진, 커널, C, 감마 등의 개�
hleecaster.com
2.3.3 선형 모델
2.3.2 k-최근접 이웃 | 목차 | 2.3.4 나이브 베이즈 분류기 – 선형 모델linear model은 100여 년 전에 개발되었고, 지난 몇십 년 동안 폭넓게 연구되고 현재도 널리 쓰입니다. 곧 보겠지만 선형 모델은
tensorflow.blog
'AI > Experiment' 카테고리의 다른 글
| 09. 나이브베이즈 분류 ( Naive Bayse classification ) (0) | 2020.05.21 |
|---|---|
| 07. 로지스틱 회귀( Logistic Regression ) (0) | 2020.05.18 |
| 06. 선형 회귀의 한계점 (0) | 2020.05.17 |
| 05. 릿지 회귀, 라쏘 회귀 ( Ridge, Lasso ) (0) | 2020.05.15 |
| 04. 다항 회귀( Polynomial Regression ) (0) | 2020.05.14 |